ヘッドレスブラウザを使ってみる
こんにちは。i-Vinciのakiyoshiです。
同じ画面でひたすら値を変えてポチポチしていたときに、以前スクレイピングしていた時に使っていたヘッドレスブラウザならラクできそうだなと思い、引っ張り出してみました。
ヘッドレスブラウザのデモがてら、画面の入力フォームに値を入れたり、スクリーンショットを撮っています。
また、今回は実際のWEBサイトを対象にすると迷惑がかかるかもしれないので、自前で画面を用意しました。
ろくなスタイルも当たっていないのはご愛敬ということで。。
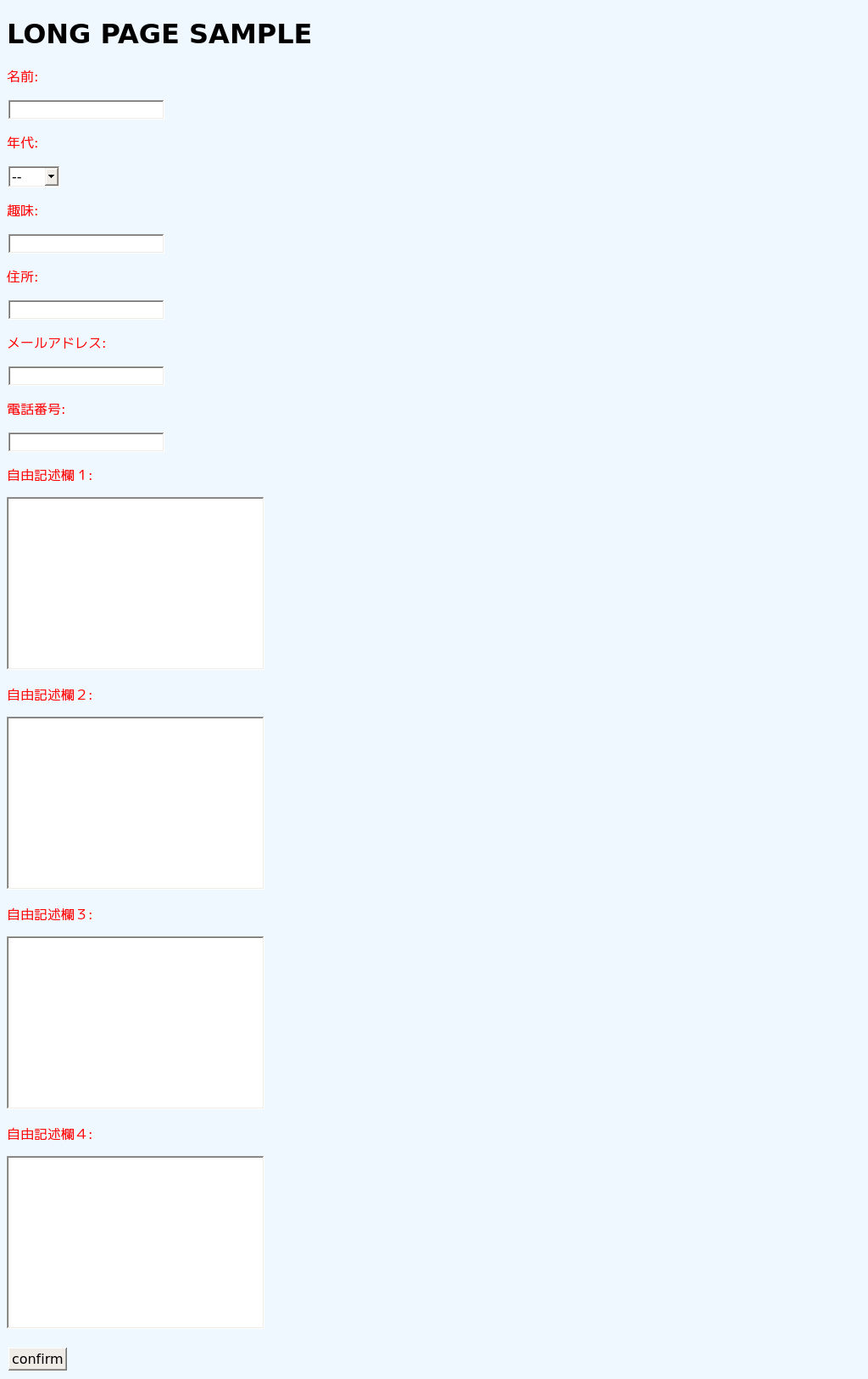
今回使った画面(sinatraで立てました)
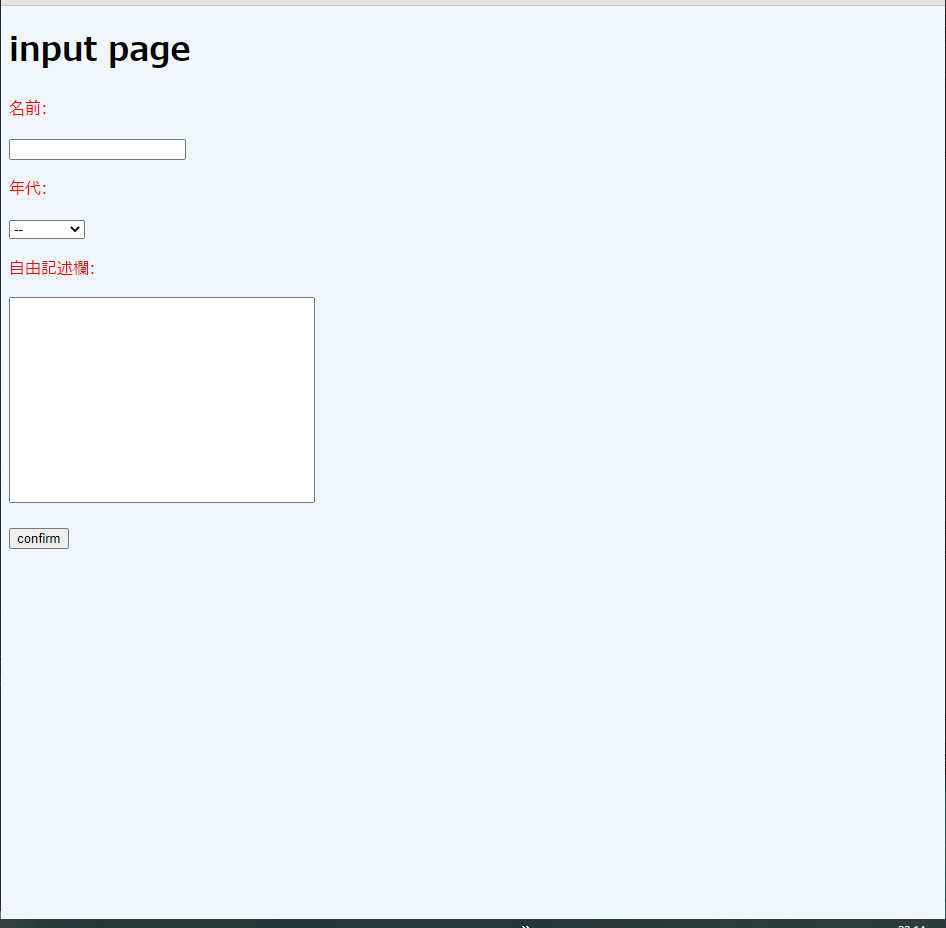
道具選び
前提として以下を利用しています。
- CentOS7
- Ruby(ruby 3.1.1p18 (2022-02-18 revision 53f5fc4236) [x86_64-linux])
- gem 'nokogiri'
- gem 'poltergeist'
- gem 'capybara'
ブラウザ
今回は趣味でヘッドレスブラウザ「PhantomJS」を利用しますが、
今後同じようなことをしたい場合は「Google Chrome」のヘッドレスモードを使った方が良いかもしれません。
というのも、「PhantomJS」はすでに開発の一時停止が宣言されており、JavaScriptへ対応できないことが増えてくる懸念があるためです。
ソースなど参考にするというよりは、ヘッドレスブラウザでこんなことができるんだ程度で読んでいただけると幸いです。
ともかく、ブラウザをインストールします。
sudo yum -y install epel-release
sudo rpm -ivh http://repo.okay.com.mx/CentOS/7/x86_64/release/okay-release-1-1.noarch.rpm
sudo yum -y install phantomjs
~省略
Failing package is: phantomjs-2.5.0-1.el7.x86_64
GPG Keys are configured as: file:///etc/pki/rpm-gpg/RPM-GPG-KEY-OKAY
$ phantomjs -v
-bash: phantomjs: command not foundむぅ。私はphantomjsのインストールで詰まったため、暫定措置で/etc/yum.repos.d/okay.repoのgpgcheckを0にして対応しました。※要するにGPG署名を無視しています。
対処法の王道をご存じの方教えてください。
ソースコード
require 'capybara'
require 'capybara/dsl'
require 'capybara/poltergeist'
class Scrape
include Capybara::DSL
def initialize()
Capybara.register_driver :poltergeist do |app|
Capybara::Poltergeist::Driver.new(app, {
js_errors: false,
timeout: 5000,
# debug: true, コメント解除でコンソール上に処理状況が吐き出される
phantomjs_options: [
'--load-images=no',
'--ignore-ssl-errors=yes',
'--ssl-protocol=any']})
end
Capybara.default_driver = :poltergeist
end
def visit_input_page
#ユーザエージェント設定(必要に応じて)
page.driver.headers = { "User-Agent" => "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36" }
# 対象画面を開く
visit('http://localhost:4567/input')
#スクリーンショット保存
page.save_screenshot(rtn_ss_name)
# 入力フォームに値をセット
page.first('input').native.send_key('akiyoshi')
page.select('30', :from => 'age')
page.find('textarea').native.send_key('操作対象はタグやクラス、IDで指定することができます。')
page.save_screenshot(rtn_ss_name)
page.find('input.btn').click
page.save_screenshot(rtn_ss_name)
# page.find('input.btn').clickと指定の仕方は違うが、やってることは同じ。
page.click_button('submit')
page.save_screenshot(rtn_ss_name, :full => true)
# NokogiriでHTMLをパースする。今回は使っていないが、本格的にスクレイピングする場合は本命。
doc = Nokogiri::HTML.parse(page.html)
puts doc.title
end
end
# スクリーンショット名(ファイル名重複時の上書き防止)を作る
def rtn_ss_name
dir_name = './screenshot'
base_file_name = 'scrape'
unless Dir.exist?(dir_name)
Dir.mkdir(dir_name)
end
i = 1
loop{
file_name = "#{dir_name}/#{base_file_name}_#{i}.png"
unless File.exist?(file_name)
return file_name
end
i += 1
}
end
# 実行部
scrape = Scrape.new
scrape.visit_input_page動かしてみる
ruby scrape.rbん・・・?
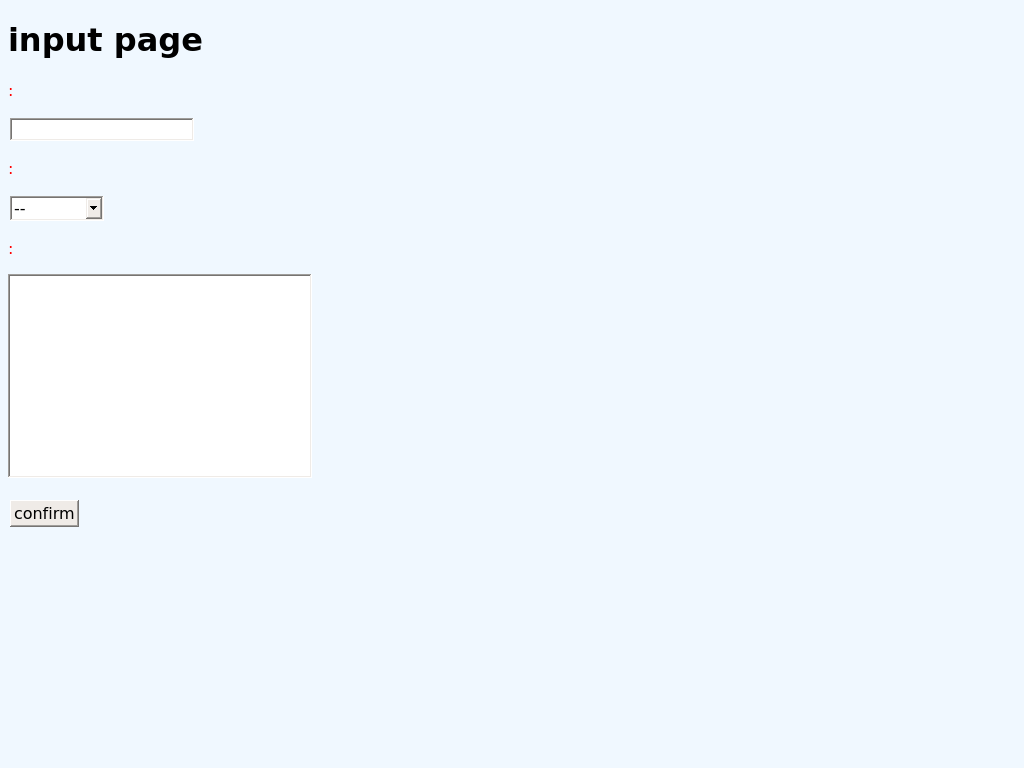
日本語が出ない
ラベル部(「名前」「年代」「自由記述欄」)が表示されていません。
「input page」という文字は出ているので、日本語が問題のようです。
想定外の挙動で一瞬思考が固まりましたが、調べたところ日本語フォントが適用されていないことが原因でした。以下で無事解決。
# 日本語フォントをインストール
yum install ibus-kkc vlgothic-*
# キャッシュをクリア
fc-cache -fv再実行
こんな感じで動いてるよー。というスクリーンショットだけ張っておきます。
本記事冒頭のスクリーンショット(ホスト側(windows)の「GoogleChrome」で表示したもの)と比較してみると、
フォント、セレクトボックス、ボタンのレイアウトに差が出ています。
表示調整の仕方もあるのかもしれませんが、厳密なレイアウト確認を行いたい場合は少し考えたほうが良いですね。
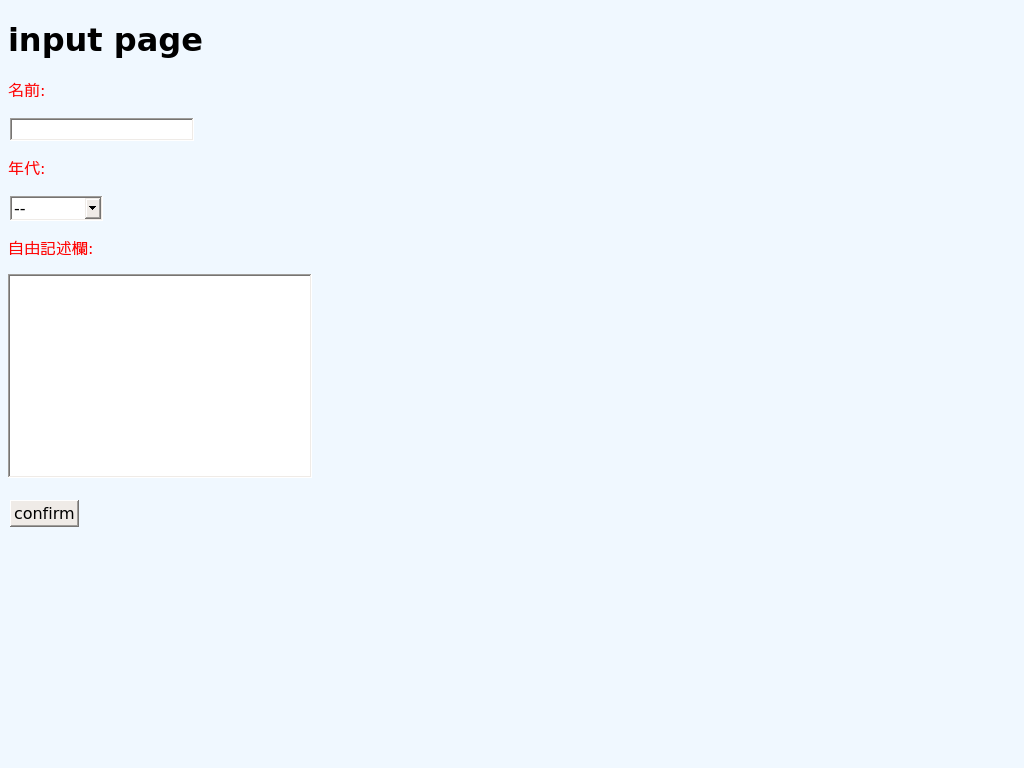

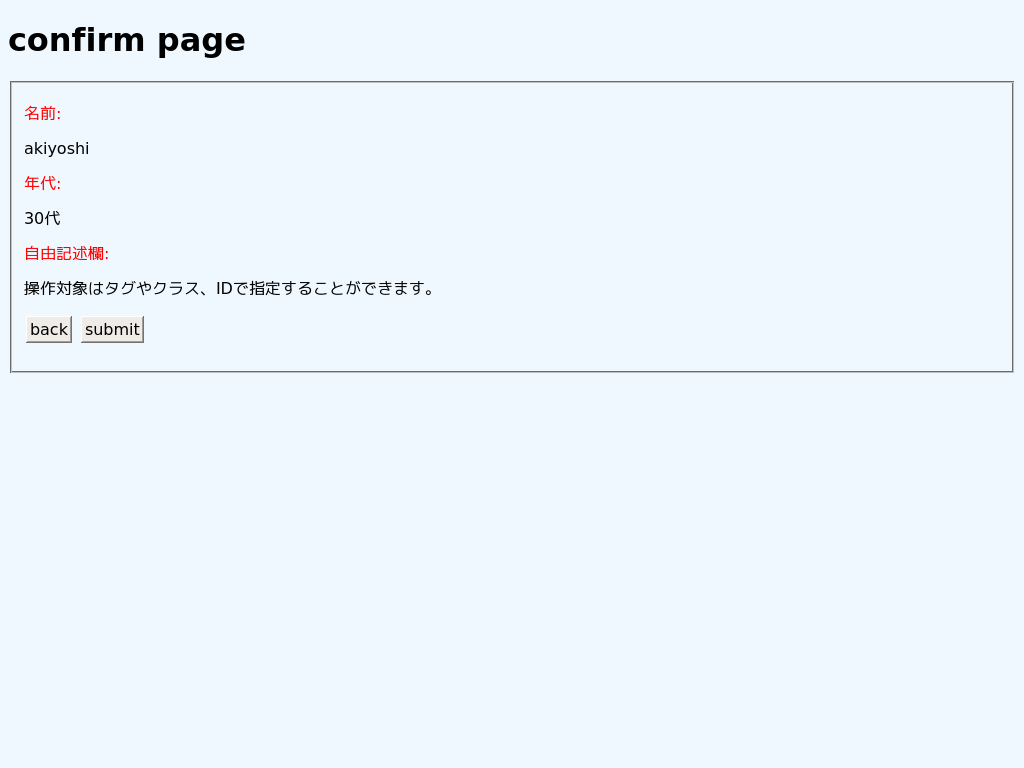
まとめ
最近はスクレイピングで調べると、「Python」が最初に出てくるこのご時世。
わざわざ「Ruby」で、それもメンテナンスが打ち切られたブラウザを使う人はいないかもしれないですが、自分はこんなことに興味があってやったことがあるんだな、ということをブログという形で残してみました。